TokenCut: Segmenting Objects in Images and Videos with Self-supervised Transformer and Normalized Cut
(CVPR 2022) Self-Supervised Transformers for Unsupervised Object Discovery using Normalized Cut
Yangtao Wang1 Xi Shen2 Yuan Yuan3 Yuming Du4 Maomao Li2 Shel Xu Hu5 James L. Crowley1 Dominique Vaufreydaz1
Univ. Grenoble Alpes, CNRS, Grenoble INP, LIG, 38000 Grenoble, France1
Tencent AI Lab2
MIT CSAIL3
LIGM (UMR 8049) - Ecole des Ponts, UPE4
Samsung AI Center, Cambridge5
Seg. for Video: [Paper] [GitLab] [GitHub]
Seg./Det. for Image:
[GitLab]
[GitHub]
![]()
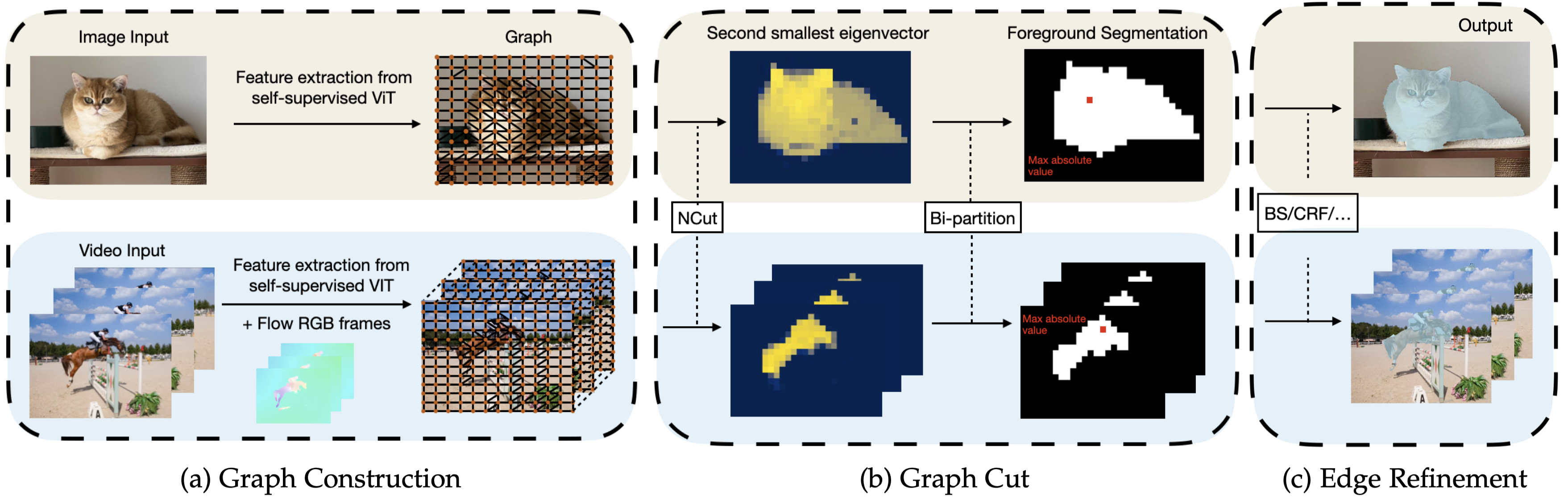
|
Visual Results
Segmentation Results
Video Segmentation
 |
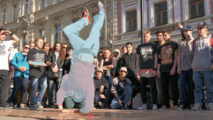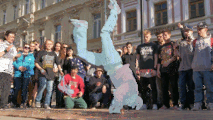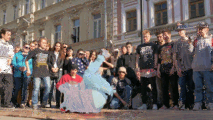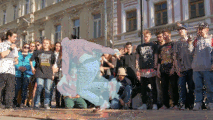 |
 |
|||
|---|---|---|---|---|---|
 |
 |
 |
More result on DAVIS, FBMS and SegTrackv2
Image Segmentation
| Raw Image | TokenCut | TokenCut + Bilateral Solver | |||
 |
 |
 |
|||
 |
 |
 |
|||
 |
 |
 |
|||
 |
 |
 |
More results on ECSSD, DUTS and DUT-OMRON
Detection Results
| Raw Image | EigenVector Attention | Detection(Red) | |||
 |
 |
 |
|||
 |
 |
 |
|||
 |
 |
 |
|||
 |
 |
 |
More results on VOC07, VOC12 and COCO
Internet Image Results
| Raw Image | Attention | Detection | |||
 |
 |
 |
|||
 |
 |
 |
Code and Paper
 Code(Seg./Det. for Image) |
 Demo |
 Paper1(CVPR) |
 Code(Seg. for Video) |
 Paper2(arXiv) |
|---|
To cite our paper,
@inproceedings{wang2022tokencut,
title={Self-supervised Transformers for Unsupervised Object Discovery using Normalized Cut},
author={Wang, Yangtao and Shen, Xi and Hu, Shell Xu and Yuan, Yuan and Crowley, James L.
and Vaufreydaz, Dominique},
booktitle={Conference on Computer Vision and Pattern Recognition},
address = {New Orleans, LA, USA},
month = {June},
year={2022}
}
@unpublished{wang2022tokencut2,
title = {{TokenCut: Segmenting Objects in Images and Videos with Self-supervised Transformer
and Normalized Cut}},
author = {Wang, Yangtao and Shen, Xi and Yuan, Yuan and Du, Yuming and Li, Maomao and
Hu, Shell Xu and Crowley, James L and Vaufreydaz, Dominique},
url = {https://hal.archives-ouvertes.fr/hal-03765422},
note = {working paper or preprint},
year = {2022},
hal_id = {hal-03765422},
hal_version = {v1}
}
Acknowledgements |